- XPath in Selenium webdriver
- Xpath with Tagname
- Xpath with Index
- Xpath with Attribute
- Xpath With Parent Reference in selenium
- Xpath with Group Index
- text() function in Xpath
- Wild card Character with Xpath in Selenium python
- Dependent and Independent Xpath
- contains() function in Xpath
- starts-with and ends-with functions xpath
- Last() function in Xpath
- Position function in Xpath
- CaSe in-sensitive Xpath in selenium webdriver
- Attribute value's Length xpath in selenium
- Relational value Xpath in selenium webdriver
- Axes in Xpath in selenium webdriver
- Forward Axes in XPath in selenium
- Reverse Axes in Xpath selenium
XPath in Selenium webdriver
Xpath is nothing but an XML path, and the developer used XPath to validate XML files. HTML also follows the same structures as XML so that we can apply XPath to HTML pages as well along with selenium webdriver.
Xpath is nothing but sting expression which used to find the element(s) along with Selenium Webdriver, and other automation tools.
Syntax of XPath
Xpath follows straightforward syntax; please find below the image for the XPath syntax.

HTML code Syntax

HTML code can have n-number of attributes, text and closing tag is not mandatory for a few elements.
There are two kinds of xpaths
1. Absolute XPath
2. Relative XPath
Absolute Xpath
/ - point to the first node on the HTML document, it is HTML tag

Relative Xpath
// - points to anywhere in the webpage

- tagName - tag name is nothing but the name which is present after the < (angular bracket)
- attribute - whatever is present inside < and > bracket except tagname is an attribute, any number of attributes can present in HTML code
- attribute's value - it is corresponding value to the attribute, sometimes for boolean attribute developers may not specify any value; in those cases, HTML takes 'true' as default value.
- Text - text is the value present inside > and <
Now let's form the xpath for the above HTML code.
//a[@class='idle']Vide for XPath
Xpath with Tagname
We can write Xpath based on Tagname, which is very simple.
<button type="button">Blueberry</button><br><br>In the above code, there is a button present under div. we can write the XPath with tagname:
//buttonXpath with Index
We may not see unique HHTML tag names on the webpage other than on the login page. Please save the below HTML file as composite-xpath.html on your local machine.
<html>
<body>
<div id="pancakes">
<button type="button">Blueberry</button><br><>
<button type="button">Banana</button><br><br>
<button type="button">Strawberry</button><br><br>
</div>
</body>
</html>Open the above HTML file in chrome, and press F12, or right-click on the element and choose Inspect Elementor or Press Ctrl+Shift+I. It may look like the below image once you open the chrome developer tool.
Press Ctrl+F to verify Xpath, and write the XPath based on the XPath syntax.
Xpath based on the Tagname : //button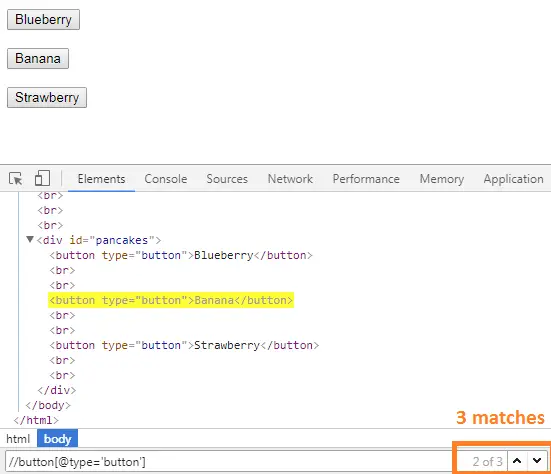
When you try the XPath with tagname, it shows three matches, so we cannot proceed as we want to find only one match. We must write an XPath expression that should have only one match. When we have a matching element only under one parent(this case), we should add an index to the XPath.
Syntax for Xpath with Index : //tagName[index]Index must be covered with square('[',']') brackets. Index starts from 1 in xpath

Xpath for the elements :
Bluberry button- //button[1]
Banana button - //button[2]
Strawberry button -//button[3]Xpath with Attribute
We can use index type XPath with webdriver when we have more matches under one parent; the index might not work if there are more parents.
Store below HTML in the local system and open it with chrome.
<html>
<body>
<div id="pancakes">
<button type="button">Blueberry</button><br><br>
<button type="button" name='banana' >Banana</button><br><br>
<button type="button">Strawberry</button><br><br>
</div>
<div id="pancakes">
<button type="button">Apple</button><br><br>
<button type="button">Orange</button><br><br>
<button type="button">Grape</button><br><br>
</div>
</body>
</html>Let's try to write XPath for Banana button, Xpath based on an index is //button[2], but it has two matches 1. Banana, 2.Orange. With an index, we may not be able to solve this issue.
Let's consider other properties of the HTML element; banana has an attribute name, Now we have to form the XPath based on the attribute.
Xpath with Attribute ://tagName[@attribute='attribute value']Xpath based on the Attribute is : //button[@name='banana'], this XPath shows only one match which is Banana button.
You can add n number attributes in one XPath itself
Xpath with multiple Attributes:
//tagName[@attrib='attrib value'][@attrib2='attrib2 value']...Can I use an index along with an attribute? yes, you can use it, but the index will be useful only when matches are under a single parent.
Xpath with Attribute and Index:
//tagName[@attribute='attribute value'][index]Xpath With Parent Reference in selenium
We cannot expect an HTML element to have different or uniques properties all the time. Sometimes there is a chance that every element may have the same kind of attributes, In those cases, we cannot use Xpath with Attribute in the selenium.
To handle such kinds of cases we may need to take the help of the parent element to find our actual element. Store the below code in an HTML file and open it in chrome.
<html>
<body>
<div id="berry">
<button type="button">Blueberry</button><br><br>
<button type="button">Banana</button><br><br>
<button type="button">Strawberry</button><br><br>
</div>
<div id="fruit">
<button type="button">Apple</button><br><br>
<button type="button">Orange</button><br><br>
<button type="button">Grape</button><br><br>
</div>
</body>
</html>Let's write XPath for Orange, using the parent and child concept. The syntax for Xpath with parent and child

For the Orange element, we have to refer to its parent div which has id attribute as fruit Xpath for the Orange: //div[@id='fruit']/button[2]
We have only one match for the XPath we have written.
Explanation for Xpath : //div[@id='fruit']/button[2]
// - look for any node which has 'div' as tagname and id as fruit, look for immediate child(/) node which has tagname as a button and at the index of 2.
Xpath with Group Index
Sometimes we may have to handle the elements with the XPath index, but the index may give more than one match, which are under different parents; in these situations, the index might not help you. We may have to use the Group index in this kind of scenarios
Group index puts all matches into a list and gives indexes to them without considering under what parent they are in. So here we will not have any duplicates matches. We have to use parenthesis to make an xpath into group XPath after it indexes the XPath.
Syntax : (//tagName)[index]Store below HTML code into HTML file :
<html>
<body>
<div id="fruit"><br><br><br>
<button type="button">Blueberry</button><br><br>
<button type="button" >Banana</button><br><br>
<button type="button">Strawberry</button><br><br>
</div>
<div id="fruit">
<button type="button">Apple</button><br><br>
<button type="button" >Orange</button><br><br>
<button type="button">Grape</button><br><br>
</div>
</body>
</html>Let's write XPath for Orange : (//button)[5]
text() function in Xpath
There will be situations, where you may not be able to use any HTML property other than text present in the element. text() function helps us to find the element based on the text present in the element, text() function is case sensitive.
<button type="button">Blueberry</button><br><br>In the above code, the text is Blueberry, and we can write XPath using text () like below
xpath with text : //button[text()='Bluberry']Note: we use @ sign for attributes, functions do not need @ sign. We can also match element(s) which have text in them with the below XPath.
xpath with text ://button[text()]
://button/text()Wild card Character with Xpath in Selenium python
- * - is the one of most used wild card characters with xpath in selenium webdriver, we can use it instead of the tag name and attribute.
- //* - matches all the elements present in the HTML (including HTML).
- //div/* - matches all the immediate element(s) inside the div tag.
- //input[@*] - matches all the element(s) with input tag and have at least one attribute, attribute value may or may not present.
- //*[@*] - matches all the element(s) which have at least one attribute.
Dependent and Independent Xpath
We may face scenarios where the given element may change its position every time, so to handle such kind of scenarios we have to go for dependent and independent xpaths
For example: Take any e-commerce website, search for a specific product and write xpath for that particular product, take rest for few days and then go and search for the same product, there could be a change in position of the product, to handle this we should use the dependent and independent concept.
Scenario: Select the checkbox which is present in the same row as Protractor. (if this table does not refresh then please visit, https://chercher.tech/practice/dynamic-table)
| Select | Tool | Language |
|---|---|---|
| Selenium | Java | |
| Protractor | Typescript | |
| Selenium Bindings | Python | |
| QTP | VB |
Steps to solve the scenario:
- Do not write the xpath for the checkbox, because checkboxes might change their position.
- Based on the text present in the Protractor field, we have to write the xpath
- we have to find the common parent for Protractor and Checkbox
- Xpath to find the protractor : //td[text()='Protractor']
- Now we should find the parent of the Protractor element
- We can find the parent of an element using /.. like in Unix
- Xpath for parent of Protractor : //td[text()='Protractor']/..
- Check Protractor's parent is a common parent for Protractor and checkbox.
- Yes, Protractor parent is a common parent for Protractor and checkbox
- Now try to navigate to checkbox using checkbox properties
- Checkbox has tagname as input : //td[text()='Protractor']/..//input
- Try the above xpath it will highlight the checkbox related to the Protractor field
Here Protractor is independent, and the checkbox is dependent
- Independent : It does not depend on any other element
- Dependent : We have to find this based on the other element(Independent)
contains() function in Xpath
contains() function helps the user to find the element with partial values, or dynamically changing values, contains verifies matches with a portion of the value.
contains function ://xpath[contains(@attribute, 'attribute value')]
//xpath[contains(@text(), 'attribute value')]Example of below HTML:
<html>
<body>
<div id="fruit"><br><br><br><br><br><br><br><br><br><br><br>
<button type="button">Blue berry1234</button><br><br>
<button type="button" >Banana</button><br><br>
<button type="button">Straw</button><br><br>
<button type="button">berry</button><br><br>
<button type="button">Straw berry</button><br><br>
</div>
</body>
</html>Xpath for the Blueberry : //button[contains(text(),'Blue')]
Xpath for the Banana : //button[contains(text(),'Ban')]More Complex items:
In the same way, if you try to find XPath for Straw berry with //button[contains(text(), 'Straw')], it finds the element with text Straw as well.
If you try with berry, you may get 'berry' element. So how to find the Straw berry button.
We can combine more than one contains functions like : //xpath[contains(text(), 'text1')][contains(text(), 'text2')]
Xpath for Strawberry is : //button[contains(text(),'Straw')][contains(text(), 'berry')]
Not only for the text you can apply contains function but also for other attributes as well Eg : //button[contains(@type,'but')]
starts-with and ends-with functions xpath
starts-with
Starts-with function matches the elements which property starting value
syntax ://xpath[starts-with(@attribute,'starting value')]<button type="button">Straw berry</button><br><br>Xpath for the Strawberry element ://button[starts-with(text(), 'Straw')]
ends-with function xpath
Ends-with function matches ending value of the element properties
syntax ://xpath[ends-with(@attribute,'ending value')]<button type="button">Straw berry</button><br><br>Xpath for the Strawberry element : //button[ends-with(text(), 'berry')]
Last() function in Xpath
By default, automation tools take the first instance of the match; also, if we want to achieve the first element, we can use index [1]. But on some pages, we may not be able to see how many matches are present when the page is loading or on a dynamic page.
last() function in Xpath helps the user to find the last match of the element.
last function : //xpath[last()]Take the example of below HTML code
<html>
<body>
<div id="fruit"><br><br><br>
<button type="button">Blueberry</button><br><br>
<button type="button" >Banana</button><br><br>
<button type="button">Strawberry</button><br><br>
</div>
</body>
</html>In the above, if we want to write xpath for the last element, it is easy we can say use index [3], but if the application is very large or dynamic, we cannot say how many elements are going to present.
So let's use last function in xpath : //button[last()] - points to the Strawberry button.
Position function in Xpath
Position function helps the user to get the match at a particular index, using position we can get elements that are less than the position or greater than the position as well.
position function ://xpath[position()=2]
://xpath[position()<2]
://xpath[position()>2]
://xpath[position()=<2]] ...Example : //button[position()=2]
CaSe in-sensitive Xpath in selenium webdriver
Sometimes we may have a situation where we have found the element based on the attribute. We can use @ method for an attribute, but if the attribute values change every time lower to upper case or mix case value when the page refreshes, this @ method may not help us.
During such kinds of situations, we must ignore the case(UPPER/lower). Below is the syntax to match the elements by ignoring the case, the translate method helps us to perform this.
Syntax :// tagname[text(), 'sourceCaseContent', 'targetCaseContent'), 'value']- tagname - is the HTML tag used for the element like the label, a, span, div.
- text() - text() value present in the element.
- sourceCaseContent - We have to pass the Letter(s) which all we want to convert 'ABCD' so on.. we can also give only a few letters like 'agk' (sourceCaseContent could be UPPER/lower case)
- targetCaseContent - We have to pass the Letter(s) to which we want to convert the SourceCaseContent, it could be in any case.
- value - the target value which we want to compare it could be any value, but it should be in the target case (if the target case is UPPER then the value also should be in upper
Html code : <label id="aBcK" name='p'>SEleNiuM</label>
Xpath ://label[contains(translate(text(),'CDEILMNSU','cdeilmnsu'),'selenium')]Attribute value's Length xpath in selenium
We can find the element based on the attribute value/text length in selenium, the string-length() method helps us to form the xpath based on the element's attribute length.
yntax :// tagname[string-length(@attibute's name/text)= expectedLength]- tagname - is the HTML tag used for the element like the label, a, span, div..
- @attribute's name - any attribute present in the element like id, name, src, href... text () - text() value present in the element.
- expectedLength - numeric expected length of the attribute value or text value
Html code : <label id="twinkie" name='p'>selenium</label>
Xpath ://label[string-length(@id) = 7]
Xpath ://label[string-length(text()) = 8]
twinkie - 7 letters
selenium - 8 lettersRelational value Xpath in selenium webdriver
We can form xpath based on the numeric attribute value/text present in the element with relational operators. For example, we can find the elements which have numeric text greater than 40 or less than 70 like so
Syntax :// tagname[@atrribute/function > expectedValue]- @atrribute/function - should result in numeric value
- expectedValue - Must be a numeric value
Html code : <label id="50" name='p'>30</label>
Xpath 1 ://label[text()>20]
Xpath 2 ://label[@id()<70]
Xpath 3 ://label[@id()<70][text()>20]
Axes in Xpath in selenium webdriver
XPath axes are used to identify elements that periodically change or refresh their attributes by their relationship like a parent, child, sibling, based on the independent element, whose properties do not change.
Axes refer to the node on which elements are lying relative to an independent element. We could traverse in both forward and reverse directions.
Forward Axis :
|
|
|
|
|
|
|
Reverse Axis :
|
|
|
|
|
Save the below code as an HTML file
<html>
<head></head>
<body>
<div name='username'>
<label id="user">Username</label>
<input id="username" type="text">
</div>
<div name='password'>
<label id="pass">Password</label>
<input id="username" type="password">
</div>
</body>
</html>Forward Axes in XPath in selenium
The forward axis in XPath helps to find the element/node after the current or reference element (helps to find an element in the code that is below the current element in the HTML file).
We can narrow down the matches by adding more details about the HTML element like tag names, attributes.
self :
self specifies the current element
attribute :
attribute specifies the attributes of the current element.
Now let's narrow down to the element(s), which have an attribute id.
child :
child specifies all child elements of the current element.
We can match the element with a particular tag or ids, below one matches the child element(s) which have input as a tag.
descendant :
It specifies all the children and grandchildren elements
Narrow down to the descendant who has input as a tag
descendant-or-self :
It specifies current or all the children and grandchildren elements
Narrow down to the child who has input as a tag; if the current element has an input tag, then this xpath matches that as well.
following-sibling :
It specifies the following siblings of the current element. Siblings are at the same level as the current element and share its parent.
following :
It specifies all elements that come after the current element, which includes elements of other div's as well.
Reverse Axes in Xpath selenium
The reverse axis in xpath helps to find the element/node before the current or reference element (helps to find an element in the code that is above the current element in the HTML file).
We can narrow down the matches by adding more details about the HTML element like tag names, attributes.
parent :
It specifies the parent of the current element.
ancestor :
It specifies the ancestors of the current element/nodes, which include the parents up to the root HTML.
Narrow the matches to the element(s) which has div as HTML tag by navigating to ancestors.
ancestor-or-self :
It specifies the current element or all elements that come before the current element
Let's narrow down our search to the element which has tag as a body from the current element by navigating the reverse axis; if the current element is a body, then it matches the current element itself.
preceding-sibling :
preceding :
It specifies all elements that come before the current element (i.e. before its opening tag).
Dropdown Option selected or Not in selenium
Recommended Readings
- Find Element / Find Elements in Selenium
- Get Text, Attribute, CSS, Size values from Element in Selenium
- Sendkeys : Click : Clear : Submit ~ Element Input Operations
- Strings in Java & Selenium
- Developer tools in Firefox and Chrome | Selenium
- Get Title : URL : Page Source in Selenium
- Navigation Commands in Selenium
- Browser Size in Selenium Webdriver | maximize();
I am Pavankumar, Having 8.5 years of experience currently working in Video/Live Analytics project.